

Website
Hướng dẫn Phân tích dữ liệu bằng Python cho người mới bắt đầu

06
Th10
Th10
Bài viết dưới đây cung cấp hướng dẫn tổng quan cho những ai muốn học phân tích dữ liệu bằng Python. Nội dung tập trung vào giới thiệu các công cụ chính, các đoạn mã code và tài liệu học tập cơ bản.
I. Ứng dụng của Python trong Phân tích dữ liệu
Python đã trở thành một công cụ phổ biến trong lĩnh vực phân tích dữ liệu nhờ vào sự linh hoạt tuyệt vời. Với thư viện phong phú và cộng đồng hỗ trợ lớn, Python là lựa chọn hàng đầu cho nhiều chuyên gia phân tích dữ liệu. Các ứng dụng của Python trong phân tích dữ liệu bao gồm: xử lý dữ liệu, trực quan hóa, xây dựng các mô hình học máy phức tạp.
II. Ưu và nhược điểm khi Phân tích dữ liệu bằng Python
1. Ưu điểm
- Thư viện phong phú. Python cung cấp nhiều thư viện mạnh mẽ, giúp việc phân tích dữ liệu trở nên dễ dàng và hiệu quả.
- Dễ học và sử dụng. Python có cú pháp đơn giản, dễ đọc, phù hợp cho cả những người mới bắt đầu.
- Sử dụng thụt lề để xác định các khối mã
- Không cần khai báo kiểu dữ liệu khi tạo biến
- Nhiều cú pháp của Python gần với ngôn ngữ tự nhiên
- Thư viện tiêu chuẩn cung cấp nhiều chức năng hữu ích mà không cần cài đặt gói bên ngoài.
- Hỗ trợ lập trình hướng đối tượng
- Cấu trúc điều khiển như if, for, while rất dễ hiểu và sử dụng.
- Tổ chức mã theo các hàm và module, giúp mã dễ quản lý và tái sử dụng.
- Cộng đồng hỗ trợ lớn. Với một cộng đồng người dùng đông đảo, bạn có thể dễ dàng tìm thấy sự hỗ trợ khi gặp vấn đề. Một vài cộng đồng phổ biến mà bạn có thể tham khảo:
- Stack Overflow: Một trong những cộng đồng lập trình lớn nhất. Nơi bạn có thể đặt câu hỏi và nhận câu trả lời từ các chuyên gia Python trên toàn thế giới.
- r/Python: Một cộng đồng Reddit lớn dành cho tất cả các nhà phát triển Python, từ người mới bắt đầu đến chuyên gia.
- Python.org Community: Trang web chính thức của Python cung cấp nhiều liên kết đến các nhóm người dùng, mailing list, và các diễn đàn hỗ trợ.
2. Nhược điểm
- Hiệu suất thấp hơn. Python có thể chậm hơn so với một số ngôn ngữ khác (C, C++, Java) khi xử lý lượng dữ liệu lớn. Biện pháp khắc phục:
- Sử dụng các thư viện tối ưu như NumPy, Pandas, Dask để xử lý dữ liệu lớn vì chúng sử dụng mã C/C++ dưới lớp và được tối ưu hóa cho hiệu suất cao.
- Sử dụng mô-đun multiprocessing để chạy các tác vụ đồng thời trên nhiều lõi CPU, tránh hạn chế của GIL.
- Sử dụng Python kết hợp với các ngôn ngữ khác như C hoặc C++ để thực hiện các phần tính toán nặng.
- Sử dụng các công cụ phân tán như Apache Spark để xử lý dữ liệu lớn phân tán trên nhiều máy tính.
- Sử dụng nhiều tài nguyên. Một số thư viện của Python có thể tiêu tốn nhiều bộ nhớ và CPU.
III. Công cụ và mã code Phân tích dữ liệu cơ bản bằng Python
1. Hướng dẫn cài đặt Python
- Truy cập trang web python.org và tải phiên bản Python mới nhất.
- Chạy tệp cài đặt và làm theo hướng dẫn để hoàn tất quá trình cài đặt.
2. Cài đặt các công cụ và thư viện cần thiết
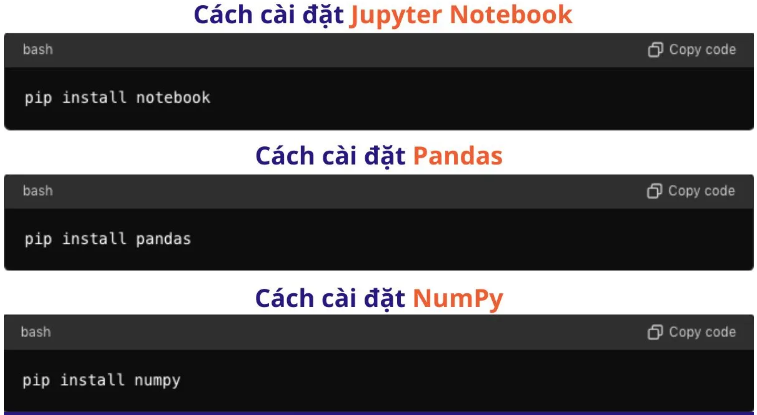
- Jupyter Notebook: Công cụ mạnh mẽ để viết và chạy mã Python
- Anaconda: Phân phối Python với nhiều gói và công cụ cần thiết. Tải và cài đặt từ anaconda.com.
- Pandas: Thư viện quản lý và thao tác dữ liệu. Pandas là thư viện mạnh mẽ cho phép xử lý dữ liệu dạng bảng một cách dễ dàng và hiệu quả. Các chức năng chính bao gồm:
- Đọc và ghi dữ liệu từ nhiều định dạng khác nhau.
- Xử lý và biến đổi dữ liệu.
- NumPy: Thư viện tính toán khoa học và số học. NumPy hỗ trợ các phép tính toán khoa học và xử lý mảng lớn một cách hiệu quả. Các tính năng nổi bật:
- Cung cấp mảng đa chiều.
- Các hàm toán học và logic.
- Matplotlib và Seaborn: Thư viện trực quan hóa dữ liệu.
- Matplotlib: Thư viện cơ bản để tạo biểu đồ.
- Seaborn: Xây dựng trên Matplotlib với giao diện đơn giản hơn và tích hợp sẵn các biểu đồ phức tạp
- Plotly: Thư viện tạo biểu đồ tương tác. Plotly giúp tạo các biểu đồ tương tác, thích hợp cho các ứng dụng web và báo cáo dữ liệu trực quan.

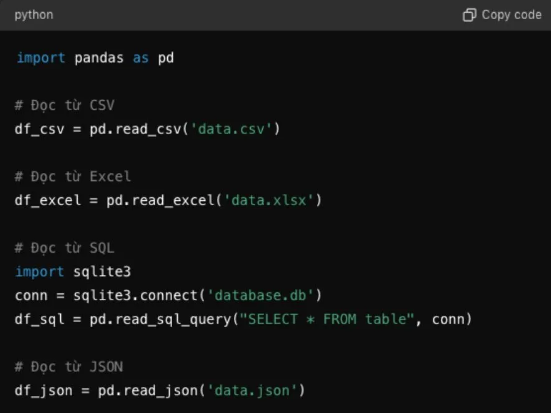
3. Đọc và xử lý dữ liệu
- Đọc dữ liệu từ các định dạng khác nhau. Pandas hỗ trợ đọc dữ liệu từ nhiều định dạng
- Xem và kiểm tra dữ liệu.
- head(): Xem những dòng đầu tiên của dữ liệu.
- info(): Kiểm tra thông tin tổng quát về dữ liệu.
- describe(): Xem các thống kê cơ bản.
- Làm sạch dữ liệu
- Xử lý giá trị thiếu
- Loại bỏ dữ liệu dư thừa
- Chuyển đổi kiểu dữ liệu: chuyển đổi sang kiểu dữ liệu số nguyên

4. Phân tích dữ liệu cơ bản
- Tính toán các chỉ số thống kê cơ bản
- mean(): Trung bình
- median(): Trung vị
- mode(): Giá trị phổ biến nhất
- std(): Độ lệch chuẩn
- Lọc và lựa chọn dữ liệu
- loc: Lựa chọn dữ liệu theo nhãn.
- iloc: Lựa chọn dữ liệu theo vị trí.
- query: Lọc dữ liệu theo biểu thức.

- Nhóm và tổng hợp dữ liệu
- groupby: Nhóm dữ liệu.
- aggregate: Tổng hợp dữ liệu.

5. Trực quan hóa dữ liệu
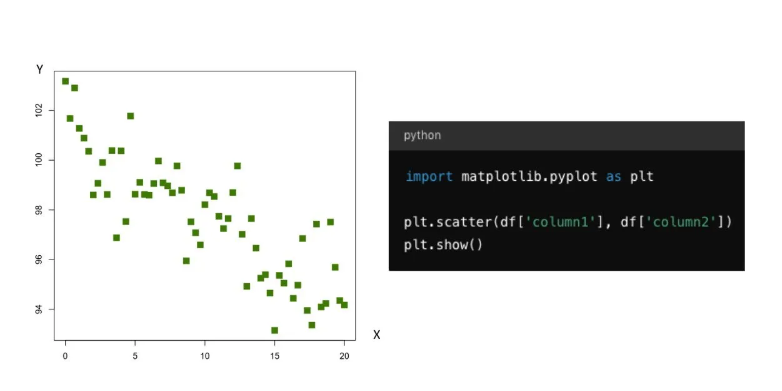
5.1. Biểu đồ phân tán (scatter plot)
- Được sử dụng để thể hiện mối quan hệ giữa hai biến số.
- Thường dùng để kiểm tra mối tương quan hoặc xu hướng giữa hai biến số liên tục.
- Mỗi điểm trên biểu đồ đại diện cho một giá trị của hai biến số.
- Có thể thêm đường hồi quy để hiển thị xu hướng chung.
- Dễ dàng nhận diện các điểm bất thường hoặc ngoại lệ
5.2.Biểu đồ cột (bar plot)
- Dùng để so sánh số lượng hoặc tần suất của các nhóm hoặc danh mục khác nhau.
- Thường sử dụng trong trường hợp dữ liệu phân loại (categorical data).
- Các cột được vẽ song song với nhau, độ cao của mỗi cột tương ứng với giá trị của danh mục đó.
- Có thể là biểu đồ cột đứng hoặc nằm ngang.
- Rất phổ biến trong các báo cáo và trình bày dữ liệu.

6. Phân tích nâng cao
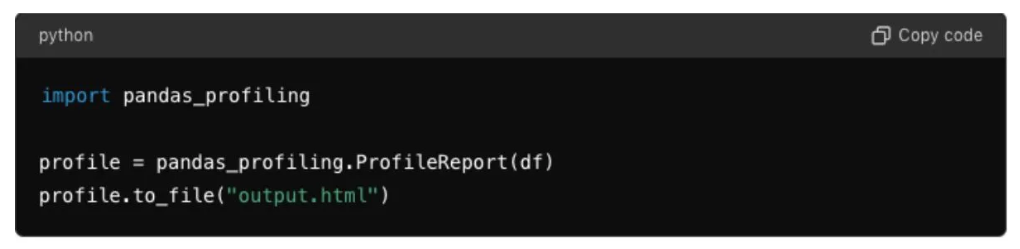
- Sử dụng Pandas Profiling để tạo báo cáo chi tiết về dữ liệu. Đặc điểm và công dụng chính của Pandas Profiling:
- Tổng quan dữ liệu: Tạo ra một báo cáo tổng quan về các biến số trong DataFrame, bao gồm số lượng, loại dữ liệu, và các giá trị duy nhất.
- Thông tin chi tiết cho từng biến số: Đưa ra các thống kê mô tả chi tiết cho từng biến số, bao gồm biểu đồ phân bố và các số liệu thống kê.
- Phát hiện các giá trị ngoại lệ: Xác định các giá trị ngoại lệ trong dữ liệu và hiển thị chúng một cách trực quan.
- Tương quan giữa các biến số: Cung cấp ma trận tương quan để hiển thị mối quan hệ giữa các biến số.
- Phân tích các giá trị thiếu: Hiển thị tỷ lệ và vị trí của các giá trị thiếu trong dữ liệu.
- Tương tác và tùy chỉnh: Báo cáo có thể được xuất ra dưới dạng HTML và hỗ trợ tương tác, cho phép người dùng dễ dàng xem xét và phân tích dữ liệu.
Sử dụng Plotly để tạo các biểu đồ tương tác
Phân tích tương quan giữa các biến
